
本文借助LangGraph基层API实现了图的构建,和大模型的接入的方法
1.手动开始构建一个图
关键词:
- State:一个在图中传输和处理的数据对象,里面维护了图的上下文记忆
- Node:可以处理数据的LLM,Tool,Function等
- Edge:用于链接两个Node,有方向
from langgraph.graph import StateGraph
# 初始化一个图构建器
# 使用StateGraph接收一个字典dict作为图的State
builder = StateGraph(dict)
builder
<langgraph.graph.state.StateGraph at 0x2b3a936e250>
# 定义两个Node
def add(state): # 接收State
# 这里接收的是init_State
print(f"init_State:{state}")
return {"x":state["x"]+1}
def sub(state):
# 这里接收的是上一个节点的状态
print(f"addition_State:{state}")
return {"x":state["x"]-2}
# 开始构建图
# START ENDS 是两个特殊的NODE,分别表示图的开始和结束NODE
from langgraph.graph import START,END
# 向图中添加NODE
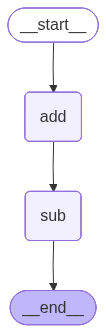
builder.add_node("add",add) # 前面是node的名字
builder.add_node("sub",sub)
# 向图中添加标EDGE
builder.add_edge(START,"add") # START->add
builder.add_edge("add","sub")
builder.add_edge("sub",END)
<langgraph.graph.state.StateGraph at 0x2b3a936e250>
builder.edges
{('__start__', 'add'), ('add', 'sub'), ('sub', '__end__')}
builder.nodes
{'add': StateNodeSpec(runnable=add(tags=None, recurse=True, explode_args=False, func_accepts={}), metadata=None, input_schema=<class 'dict'>, retry_policy=None, cache_policy=None, ends=(), defer=False),
'sub': StateNodeSpec(runnable=sub(tags=None, recurse=True, explode_args=False, func_accepts={}), metadata=None, input_schema=<class 'dict'>, retry_policy=None, cache_policy=None, ends=(), defer=False)}
# 调用compile()方法来编译为一个可以执行的图
graph = builder.compile()
from IPython.display import Image,display
# 显示graph的结构
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
# 定义一个初始化的State
initial_state = {"x":10}
graph.invoke(initial_state)
init_State:{'x': 10}
addition_State:{'x': 11}
{'x': 9}
2.借助Pydanic对象创建图
LangGraph 是一个「图式(Graph-based)AI 框架」,节点之间要传递复杂的数据(消息、上下文、工具参数等)。
- 如果这些数据没有明确结构,很容易出错。
- 所以 LangGraph 统一采用 Pydantic 模型 来: ✅ 明确每个节点的输入/输出结构 ✅ 自动校验类型和必填字段 ✅ 方便序列化/反序列化(JSON兼容) ✅ 与 OpenAI function calling、工具参数自然兼容
# pydantic的作用
from pydantic import BaseModel
class MyState(BaseModel):
x:int
y:str = "default" # 设置默认值
# 自动校验
state = MyState(x=1) # ✅ 此时做了类型校验
print(state.x)
print(state.y)
state.x = "abc" # ✅ 不再调用验证逻辑
print(state.x)
# 打开 validate_assignment 配置项让它在赋值的时候也会检查类型
class MyState(BaseModel):
x:int
y:str = "default" # 设置默认值
class Config:
validate_assignment = True
state = MyState(x=1)
state.x = "abc" # ❌ 报错
print(state.x)
# 利用pydantic来构造图
class CalcState(BaseModel):
x:int
def add(state:CalcState)->CalcState: # 接收并返回CalcState类型对象
print(f"init_State:{state}")
return CalcState(x=state.x + 1)
def sub(state:CalcState)->CalcState:
print(f"addition_State:{state}")
return CalcState(x=state.x - 2)
# 构建图
builder = StateGraph(CalcState)
# 向图中添加NODE
builder.add_node("add",add)
builder.add_node("sub",sub)
# 向图中添加标EDGE
builder.add_edge(START,"add")
builder.add_edge("add","sub")
builder.add_edge("sub",END)
# 编译
graph = builder.compile()
# 执行
initial_state = CalcState(x=10)
finial_state = graph.invoke(initial_state)
print(finial_state)
init_State:x=10
addition_State:x=11
{'x': 9}
3.构建一些特别的图
3.1含条件判断的图结构
from typing import Optional
# 利用pydantic来构造图
class MyState(BaseModel):
x: int
result: Optional[str] = None # 表示 result 可有可无(默认 None)
def check_x(state: MyState) -> MyState:
print(f"[check_x] Receive State:{state}")
return state
def is_even(state: MyState) -> bool:
return state.x % 2 == 0
def handle_even(state: MyState) -> MyState:
print("[handle_even] x 是偶数")
return MyState(x=state.x, result="偶数")
def handle_odd(state: MyState) -> MyState:
print("[handle_even] x 是奇数")
return MyState(x=state.x, result="奇数")
# 构建图
builder = StateGraph(CalcState)
# 向图中添加NODE
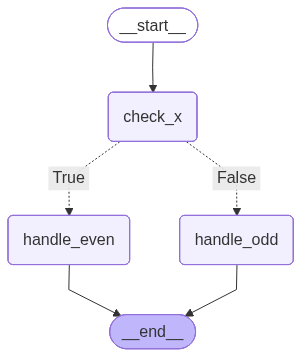
builder.add_node("check_x", check_x)
builder.add_node("handle_even", handle_even)
builder.add_node("handle_odd", handle_odd)
# 添加条件分支
builder.add_conditional_edges(
"check_x", is_even, {True: "handle_even", False: "handle_odd"}
)
# 向图中添加标EDGE
builder.add_edge(START, "check_x")
builder.add_edge("handle_even", END)
builder.add_edge("handle_odd", END)
# 编译
graph = builder.compile()
# 执行
initial_state = MyState(x=10)
finial_state = graph.invoke(initial_state)
print(finial_state)
[check_x] Receive State:x=10 result=None
[handle_even] x 是偶数
{'x': 10}
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
3.2 含循环的图结构
# 利用pydantic来构造图
class MyState(BaseModel):
x: int
def inc(state: MyState) -> MyState:
print(f"[inc] 当前 x = {state.x}")
return MyState(x=state.x + 1)
def is_done(state: MyState) -> bool:
return state.x > 10
# 构建图
builder = StateGraph(CalcState)
# 向图中添加NODE
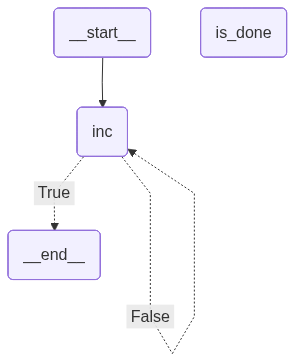
builder.add_node("inc", inc)
# 添加条件分支
builder.add_conditional_edges("inc", is_done, {True: END, False: "inc"})
# 向图中添加标EDGE
builder.add_edge(START, "inc")
# 编译
graph = builder.compile()
# 执行
initial_state = MyState(x=1)
finial_state = graph.invoke(initial_state)
print(finial_state)
[inc] 当前 x = 1
[inc] 当前 x = 2
[inc] 当前 x = 3
[inc] 当前 x = 4
[inc] 当前 x = 5
[inc] 当前 x = 6
[inc] 当前 x = 7
[inc] 当前 x = 8
[inc] 当前 x = 9
[inc] 当前 x = 10
{'x': 11}
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
3.接入大模型
3.1 初始化大模型
from dotenv import load_dotenv
import os
from langchain.chat_models import init_chat_model
load_dotenv(override=True) # (override=True) => .env 文件中的变量会 强制覆盖 系统中同名的环境变量
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY") # 通过键名(如 "PATH")获取操作系统或 .env 文件中的环境变量值
model = init_chat_model(model="deepseek-chat",model_provider="deepseek") # 初始化模型
question = "你好,请介绍一下自己"
result = model.invoke(question)
print(result)
content='你好!很高兴认识你!😊\n\n我是DeepSeek,由深度求索公司创造的AI助手。让我简单介绍一下自己:\n\n**我的特点:**\n- 📚 知识截止到2024年7月,是DeepSeek最新版本模型\n- 💬 纯文本对话模型,专注于理解和回应各种问题\n- 📁 支持文件上传功能——可以处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息\n- 🌐 支持联网搜索(需要你在Web/App手动开启)\n- 💾 拥有128K的上下文长度,能记住我们较长的对话历史\n\n**我能帮你做什么:**\n- 回答各种知识性问题\n- 协助写作、翻译、分析\n- 解释概念、提供学习指导\n- 处理和分析你上传的文档内容\n- 进行逻辑推理和问题解决\n\n**重要提醒:**\n- 我完全免费使用,没有收费计划\n- 目前不支持语音功能\n- 你可以通过官方应用商店下载App使用\n\n我的回复风格比较热情细腻,希望能给你带来愉快的交流体验!有什么问题或需要帮助的地方,尽管告诉我吧!✨' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 246, 'prompt_tokens': 9, 'total_tokens': 255, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 9}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '1892b614-4cdb-4ddc-b74d-a2f1e188ccf9', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--8cde3439-1f14-4e0a-be72-c0ce90d2f759-0' usage_metadata={'input_tokens': 9, 'output_tokens': 246, 'total_tokens': 255, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
3.2 引入大模型
然后可以把使用大模型当的node来接入到LangGraph里的StateGraph里,下一步就是统一State成大模型可识别的数据类型
from typing import Annotated # 可用于自定义类型,并携带元数据
from typing_extensions import TypedDict # 用于定义具有严格键和值类型约束的字典类型的工具
from langgraph.graph import StateGraph,START # 用于构建图的
from langgraph.graph.message import add_messages # 给langGraph 里的 State 去追加内容的
class State(TypedDict):
messages:Annotated[list,add_messages] # 表示实际是list类型,然后附带了一个add_messages函数,LangGraph 框架内部执行时,它会检测到这个字段带有 add_messages 注解,如果新赋值了messages,就会自动执行add_messages函数来合并add_messages(["old"], ["new"]) => ["old", "new"]
graph_builder = StateGraph(State) # 生成构建器
# 定义一个利用LLM来处理信息的节点
def chat_bot(state:State):
return {"messages":[model.invoke(state["messages"])]}
# 添加节点
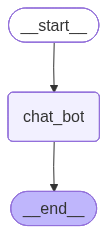
graph_builder.add_node("chat_bot",chat_bot)
# 添加边
graph_builder.add_edge(START,"chat_bot")
<langgraph.graph.state.StateGraph at 0x2b3a9374190>
graph = graph_builder.compile()
from IPython.display import Image,display
# 这是借助了服务器上返回的可视化数据
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
finally_state = graph.invoke({"messages":"你是谁?"})
# 可以发现finally_state里面含有人问,ai答的两条message
print(finally_state)
{'messages': [HumanMessage(content='你是谁?', additional_kwargs={}, response_metadata={}, id='2e618f03-bae2-4c29-b0cf-cfe0e796716f'), AIMessage(content='你好!我是DeepSeek,由深度求索公司创造的AI助手!😊\n\n我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等各种文件,并从中读取文字信息进行分析处理。我完全免费使用,拥有128K的上下文长度,还支持联网搜索功能(需要你在Web/App中手动开启)。\n\n你可以通过官方应用商店下载我的App,随时随地和我聊天!我很乐意帮你解答问题、处理文档、进行创作或者只是简单聊聊天。\n\n有什么我可以帮你的吗?我会热情细致地为你服务!✨', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 134, 'prompt_tokens': 6, 'total_tokens': 140, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 6}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'eb3a0fce-0f55-4747-8ec1-38dc855a1fc3', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--2797978d-4637-4be2-875b-ba05f75c8965-0', usage_metadata={'input_tokens': 6, 'output_tokens': 134, 'total_tokens': 140, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
for message in finally_state["messages"]:
print(message)
content='你是谁?' additional_kwargs={} response_metadata={} id='2e618f03-bae2-4c29-b0cf-cfe0e796716f'
content='你好!我是DeepSeek,由深度求索公司创造的AI助手!😊\n\n我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等各种文件,并从中读取文字信息进行分析处理。我完全免费使用,拥有128K的上下文长度,还支持联网搜索功能(需要你在Web/App中手动开启)。\n\n你可以通过官方应用商店下载我的App,随时随地和我聊天!我很乐意帮你解答问题、处理文档、进行创作或者只是简单聊聊天。\n\n有什么我可以帮你的吗?我会热情细致地为你服务!✨' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 134, 'prompt_tokens': 6, 'total_tokens': 140, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 6}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'eb3a0fce-0f55-4747-8ec1-38dc855a1fc3', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--2797978d-4637-4be2-875b-ba05f75c8965-0' usage_metadata={'input_tokens': 6, 'output_tokens': 134, 'total_tokens': 140, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
3.3 将多轮对话列表传入大模型(基于内存)
from langchain_core.messages import AIMessage,HumanMessage,SystemMessage
# 自定义以前的消息列表
messages_list = [
HumanMessage(content="你好,我叫牛伟豪,好久不见"),
AIMessage(content="牛伟豪主人,好久不见"),
HumanMessage(content="你还记得我的名字吗?"),
]
finally_state = graph.invoke({"messages":messages_list})
# 得到基于自定义多轮对话的回复
for message in finally_state["messages"]:
print(message)
content='你好,我叫牛伟豪,好久不见' additional_kwargs={} response_metadata={} id='4aa53e0e-bfe0-4d11-98f5-e4738dfea431'
content='牛伟豪主人,好久不见' additional_kwargs={} response_metadata={} id='eb508f34-0822-4366-bf60-d39ca021ba6c'
content='你还记得我的名字吗?' additional_kwargs={} response_metadata={} id='7c87f6f6-2363-4667-a606-a025ce0cf135'
content='当然记得!您的名字是牛伟豪,刚刚您已经告诉我了。很高兴能再次与您交谈!😊 有什么我可以帮您的吗?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 32, 'prompt_tokens': 30, 'total_tokens': 62, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 30}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'b4aa0bb0-c639-496b-9bfe-4f1083ba3cc4', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--2f5401e3-2a75-4562-9309-9958f5c33e6f-0' usage_metadata={'input_tokens': 30, 'output_tokens': 32, 'total_tokens': 62, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
## 3.4手动构造多轮对话机器人
messages_list = [] # 用于保存历史对话
while True:
try:
user_input = input("用户提问:")
print("USER: ",user_input)
if user_input.lower() in ["exit"]:
print("下次再见")
break
messages_list.append(HumanMessage(content=user_input)) # 手动插入对话到历史对话列表
finally_state = graph.invoke({"messages":messages_list})
print("AI: ",finally_state["messages"][-1].content)
messages_list.append(AIMessage(content=finally_state["messages"][-1].content)) # 手动插入AI回复到历史对话
except:
break
USER: 我是牛伟豪
AI: 你好,牛伟豪!很高兴认识你!😊
既然你介绍了自己,那我也自我介绍一下吧 - 我是DeepSeek,由深度求索公司创造的AI助手。我可以帮你解答问题、协助处理文档、进行对话交流等等。
有什么我可以帮你的吗?无论是学习、工作还是生活中的问题,我都很乐意为你提供帮助!或者如果你只是想聊聊天,我也很愿意陪你聊聊。✨
USER: 我是谁
AI: 根据我们之前的对话,您告诉我您是**牛伟豪**。
这就是目前我所知道的关于您的信息。如果还有其他方面您希望我了解的,或者需要我记住的关于您的特定信息(比如您的喜好、职业等),您可以随时告诉我。
那么,牛伟豪,今天有什么我可以帮助您的吗?
USER: 没有了,拜拜
AI: 好的,牛伟豪!拜拜啦!👋
很高兴和你聊天,随时欢迎你再来找我!祝你一切顺利,天天开心!😊
USER: exit
下次再见
print(messages_list)
[HumanMessage(content='我是牛伟豪', additional_kwargs={}, response_metadata={}, id='9cb02e9b-0f78-4afc-bee8-ba6b5dd71830'), AIMessage(content='你好,牛伟豪!很高兴认识你!😊\n\n既然你介绍了自己,那我也自我介绍一下吧 - 我是DeepSeek,由深度求索公司创造的AI助手。我可以帮你解答问题、协助处理文档、进行对话交流等等。\n\n有什么我可以帮你的吗?无论是学习、工作还是生活中的问题,我都很乐意为你提供帮助!或者如果你只是想聊聊天,我也很愿意陪你聊聊。✨', additional_kwargs={}, response_metadata={}, id='a300e951-ace7-493c-8c31-da8e3b4e3f9f'), HumanMessage(content='我是谁', additional_kwargs={}, response_metadata={}, id='7c1f742e-fee8-45b1-a574-a9b1d2f65cfe'), AIMessage(content='根据我们之前的对话,您告诉我您是**牛伟豪**。\n\n这就是目前我所知道的关于您的信息。如果还有其他方面您希望我了解的,或者需要我记住的关于您的特定信息(比如您的喜好、职业等),您可以随时告诉我。\n\n那么,牛伟豪,今天有什么我可以帮助您的吗?', additional_kwargs={}, response_metadata={}, id='67303056-ed4c-484f-a62d-ec0e32eadadf'), HumanMessage(content='没有了,拜拜', additional_kwargs={}, response_metadata={}, id='54938f0f-bb52-4127-a01e-2fbe2f5fbdfe'), AIMessage(content='好的,牛伟豪!拜拜啦!👋 \n\n很高兴和你聊天,随时欢迎你再来找我!祝你一切顺利,天天开心!😊', additional_kwargs={}, response_metadata={})]
3.4 借助MemorySaver搭建多轮对话API(基于内存)
from langgraph.checkpoint.memory import MemorySaver
builder = StateGraph(State)
builder.add_node("chat_bot",chat_bot)
builder.add_edge(START,"chat_bot")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
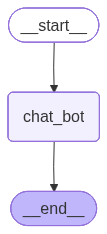
# 进行多轮对话测试,配置thread_config,用thread_id来实现记忆
thread_config = {"configurable":{"thread_id":"session_01"}}
# 第一轮对话
state1 = graph.invoke({"messages":[{"role":"user","content":"你好,我是牛伟豪"}]},config=thread_config)
state1
{'messages': [HumanMessage(content='你好,我是牛伟豪', additional_kwargs={}, response_metadata={}, id='a9c0f5b7-583e-408b-b7cf-5ac9d0508454'),
AIMessage(content='你好,牛伟豪!很高兴认识你!感谢你主动介绍自己,这让我能直接称呼你的名字,感觉我们的交流更亲切了。😊\n\n如果有什么问题需要探讨、有想分享的想法,或者需要任何帮助,无论是学习、生活还是工作中的小事,我都在这儿等着你。期待和你聊天!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 67, 'prompt_tokens': 10, 'total_tokens': 77, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'bf9d38a0-6876-47cf-96e0-9148bacfeb03', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--b6645b19-e71b-4de6-bd00-daea5d12c72e-0', usage_metadata={'input_tokens': 10, 'output_tokens': 67, 'total_tokens': 77, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
# 第二轮对话
state2 = graph.invoke({"messages":[{"role":"user","content":"我是谁,你是谁?"}]},config=thread_config)
state2
{'messages': [HumanMessage(content='你好,我是牛伟豪', additional_kwargs={}, response_metadata={}, id='a9c0f5b7-583e-408b-b7cf-5ac9d0508454'),
AIMessage(content='你好,牛伟豪!很高兴认识你!感谢你主动介绍自己,这让我能直接称呼你的名字,感觉我们的交流更亲切了。😊\n\n如果有什么问题需要探讨、有想分享的想法,或者需要任何帮助,无论是学习、生活还是工作中的小事,我都在这儿等着你。期待和你聊天!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 67, 'prompt_tokens': 10, 'total_tokens': 77, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'bf9d38a0-6876-47cf-96e0-9148bacfeb03', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--b6645b19-e71b-4de6-bd00-daea5d12c72e-0', usage_metadata={'input_tokens': 10, 'output_tokens': 67, 'total_tokens': 77, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}),
HumanMessage(content='我是谁,你是谁?', additional_kwargs={}, response_metadata={}, id='0fe6a45d-b933-4349-b076-913f6d577318'),
AIMessage(content='你好,牛伟豪!根据我们之前的对话,你刚刚介绍过自己是**牛伟豪**,而我是DeepSeek,一个由深度求索公司创造的AI助手。😊\n\n**关于你:**\n- 你刚刚告诉我你的名字是牛伟豪\n- 除此之外,我还不了解其他信息,因为我们才刚刚开始对话\n\n**关于我:**\n- 我是DeepSeek,一个AI助手\n- 我可以帮你回答问题、处理文档、进行对话交流等\n- 我支持上传各种文件(图像、txt、pdf、ppt、word、excel等)并从中读取文字信息\n- 我是免费的,目前没有收费计划\n- 我的知识截止到2024年7月\n\n如果我们之前有过更多交流,我可能会了解更多关于你的信息,但看起来我们才刚刚开始这段对话呢!如果你想让我了解更多关于你的情况,随时可以告诉我哦~\n\n有什么我可以帮你的吗,伟豪?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 196, 'prompt_tokens': 86, 'total_tokens': 282, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 64}, 'prompt_cache_hit_tokens': 64, 'prompt_cache_miss_tokens': 22}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'af0d6e5d-a5d2-451c-90d7-d4e3259eb9d7', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--f7396822-b5fb-44a1-9946-24e3ecce178b-0', usage_metadata={'input_tokens': 86, 'output_tokens': 196, 'total_tokens': 282, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}})]}
# 获取thread_config的历史对话
latest = graph.get_state(thread_config)
print(latest.values["messages"])
[HumanMessage(content='你好,我是牛伟豪', additional_kwargs={}, response_metadata={}, id='a9c0f5b7-583e-408b-b7cf-5ac9d0508454'), AIMessage(content='你好,牛伟豪!很高兴认识你!感谢你主动介绍自己,这让我能直接称呼你的名字,感觉我们的交流更亲切了。😊\n\n如果有什么问题需要探讨、有想分享的想法,或者需要任何帮助,无论是学习、生活还是工作中的小事,我都在这儿等着你。期待和你聊天!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 67, 'prompt_tokens': 10, 'total_tokens': 77, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'bf9d38a0-6876-47cf-96e0-9148bacfeb03', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--b6645b19-e71b-4de6-bd00-daea5d12c72e-0', usage_metadata={'input_tokens': 10, 'output_tokens': 67, 'total_tokens': 77, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), HumanMessage(content='我是谁,你是谁?', additional_kwargs={}, response_metadata={}, id='0fe6a45d-b933-4349-b076-913f6d577318'), AIMessage(content='你好,牛伟豪!根据我们之前的对话,你刚刚介绍过自己是**牛伟豪**,而我是DeepSeek,一个由深度求索公司创造的AI助手。😊\n\n**关于你:**\n- 你刚刚告诉我你的名字是牛伟豪\n- 除此之外,我还不了解其他信息,因为我们才刚刚开始对话\n\n**关于我:**\n- 我是DeepSeek,一个AI助手\n- 我可以帮你回答问题、处理文档、进行对话交流等\n- 我支持上传各种文件(图像、txt、pdf、ppt、word、excel等)并从中读取文字信息\n- 我是免费的,目前没有收费计划\n- 我的知识截止到2024年7月\n\n如果我们之前有过更多交流,我可能会了解更多关于你的信息,但看起来我们才刚刚开始这段对话呢!如果你想让我了解更多关于你的情况,随时可以告诉我哦~\n\n有什么我可以帮你的吗,伟豪?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 196, 'prompt_tokens': 86, 'total_tokens': 282, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 64}, 'prompt_cache_hit_tokens': 64, 'prompt_cache_miss_tokens': 22}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': 'af0d6e5d-a5d2-451c-90d7-d4e3259eb9d7', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--f7396822-b5fb-44a1-9946-24e3ecce178b-0', usage_metadata={'input_tokens': 86, 'output_tokens': 196, 'total_tokens': 282, 'input_token_details': {'cache_read': 64}, 'output_token_details': {}})]